

The population size needed for Newt is smaller than in typical GA applications for a number of reasons. First, each individual in the population is capable of learning from feedback during its lifetime between two generations. The lack of diversity due to a smaller population will be compensated for by the learning mechanism. Considering the information filtering application domain, there is also much less change across generations than in typical applications of GA. A significant proportion of user interests is likely to stay stable, or change gradually at best. This application of GA is more like a slow evolution of population which continually adapts to environmental changes, as opposed to a directed search like, say, parameter optimization. Besides, the fundamental requirement of the population of specialized profiles is that they should at least cover the complete set of known user interests. In addition to this, they may have some extra profiles to explore the information space. Having a very large population will have the undesirable effect of retrieval of uninteresting documents. Finally, since the user decides the fitness of profiles by providing feedback, the greater the number of profiles, the greater the overhead of using such a system for the user. While it will vary across users, typical users would find few tens of profiles sufficient for most information needs. The actual size would depend on the capacity of the user to devour information, the amount of information available on the networks and the proportion thereof that is actually of (potential) interest to the user.
In the current implementation, all genetic operators are entirely user controlled.
It is possible to either apply genetic operators to individual members of the
population, or apply the ``new generation'' operator to the entire population.
The effects of each of these operators is just as described in Section  .
.
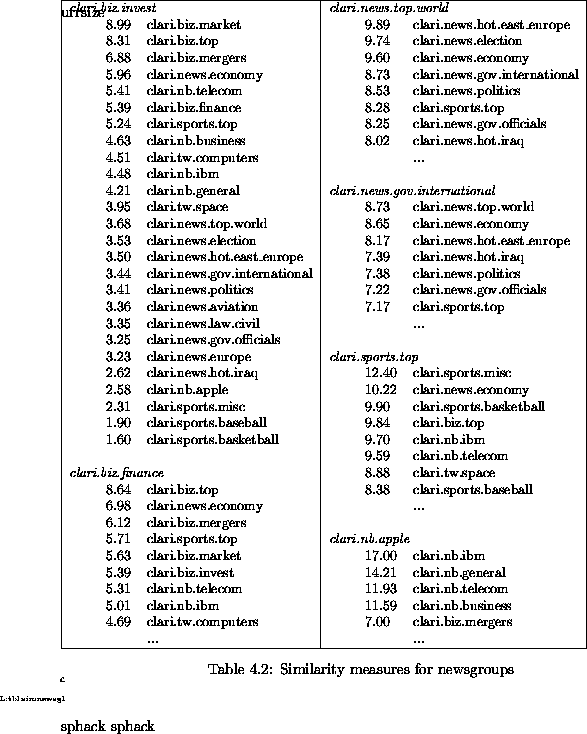
The mutation operator requires similarity measures between newsgroups. As
described in Section ,
similarity is measured based on the correlation of frequently used terms in
the two newsgroups. On typical USENET servers, the set of articles in a newsgroup
changes on a continual basis. Strictly speaking, similarities should be measured
at the time of mutation, so that the most up-to-date information is used. However,
it is currently almost impossible to evaluate in real time similarity between
two newsgroups, each of which could have up to thousands of articles. A more
practical solution has been adopted by computing a priori similarities
among newsgroups. The similarities are re-computed only once a week. The implicit
assumption is that while the articles in the newsgroups change quite frequently,
the commonly used terms in the newsgroup change much more slowly.
Table
shows the results of one such computation. Similarity measures were computed
for all pairs of newsgroups from a set of 27 newsgroups.