


Next: Discussion
Up: Results
Previous: Thoughtfulness
The counterpart of thoughtfulness is speed. The action selection behavior
can be made faster by varying the threshold 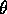 as
explained above. The resulting action selection is however less
`thoughtful', which means that it is less goal-oriented, less situation
oriented, that it takes conflicting goals less into account and that it
is less biased towards ongoing plans. Nevertheless. it may sometimes
be important
to react fast or it may be a wasted effort to be very thoughtful
(i.e., make a lot of plans and predictions).
as
explained above. The resulting action selection is however less
`thoughtful', which means that it is less goal-oriented, less situation
oriented, that it takes conflicting goals less into account and that it
is less biased towards ongoing plans. Nevertheless. it may sometimes
be important
to react fast or it may be a wasted effort to be very thoughtful
(i.e., make a lot of plans and predictions).
Fortunately, the algorithm is not complex, so that it allows speed to be
obtained without sacrificing too much thoughtfulness. The algorithm does
however perform some sort of `search' through a network from goal modules to
executable modules, so one could argue that the algorithm suffers from
the same problems as traditional AI search. More specifically, that the
efficiency necessarily goes down as the number of modules involved in a
plan grows (the so-called `combinatorial explosion' problem).
Nevertheless, it is important to take the following counterarguments into
consideration:
- The search that is going on here is of a very different nature.
Actually, it resembles marker passing algorithms more than the
AI notion of search. The system does not construct a search tree, nor does it
maintain a current hypothetical state and partial plan. In addition, it
evaluates different paths in parallel, so that it does not have to start
from scratch when one path does not produce a solution, but smoothly moves
from one plan to another. As a result, the computation the algorithm performs
is much less costly.
- The system does not `replan' completely at every timestep. The algorithm
does not reinitialize the activation-levels to zero whenever an action has
been taken. This implies that it may take some time to select the first
action to execute, but from then on, the network is biased towards
that particular situation and set of goals. This means that it will
take much less time for the following actions to be selected, in particular
when little has changed in the meantime with respect to the goals or current situation.
- We believe that for real autonomous agents (e.g., mobile robots)
the networks will
grow `larger' instead of `longer', because typically, the agent will
have more tasks/goals instead of having tasks/goals that require more actions
to be taken (and therefore more `planning'). Also, large subparts may exist in the
network that
appear to be unconnected. As a result, the efficiency of the system will not
be affected so much. Even if some paths from state matchers to goal
achievers would be very long, the system would still come up with an action
because it does not await a convergence in the activation levels and
decreases the threshold with time. The selected action might however be non
optimal.
- The same simple spreading activation rules are applied to each of the
modules. In addition, there are only local and fixed links among modules.
This opens interesting opportunities for a massively parallel implementation,
which would imply a considerable speed up.
Next: Discussion
Up: Results
Previous: Thoughtfulness
Alexandros Moukas
Wed Feb 7 14:24:19 EST 1996