


A problem with the current algorithm is that loops in the action selection may
emerge. They only occur very rarely and spring from the fact that
the system does not maintain a history of what it did before. It is questionable whether a
solution to such impasses should be built in. The hypothesis could be adopted
that in a real environment the state and goals will change anyway after some
time 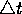 that is very small. This changes the spreading
activation patterns and therefore gets the network out of its impasse.
If we insist on avoiding (even temporal) impasses, this cannot be guaranteed
by a careful selection of the parameters. One very simple solution however
could be to introduce some randomness in the system. Another solution might
be to use a second network to monitor possible loops in the first network
and take actions whenever this happens. Finally, we could implement some
habituation mechanism for some or all of the modules. This mechanism
would take care that every time a module is activated, it is less likely to
become active in the future (i.e., have local thresholds that vary over
time).
that is very small. This changes the spreading
activation patterns and therefore gets the network out of its impasse.
If we insist on avoiding (even temporal) impasses, this cannot be guaranteed
by a careful selection of the parameters. One very simple solution however
could be to introduce some randomness in the system. Another solution might
be to use a second network to monitor possible loops in the first network
and take actions whenever this happens. Finally, we could implement some
habituation mechanism for some or all of the modules. This mechanism
would take care that every time a module is activated, it is less likely to
become active in the future (i.e., have local thresholds that vary over
time).