
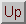




The performance measures used are precision and recall. These measures are well known and commonly used to evaluate the performance of information retrieval systems. Precision is the number of retrieved articles that were relevant. Recall is the number relevant articles that were retrieved. This experiment evaluates the behavior of precision and recall over successive user sessions. The database does not change over the duration of this experiment. Recall is calculated by manually going through each of the articles in the newsgroups searched by the profile. Each article is classified as relevant if the major topic of the news story was associated with China. Fortunately, the articles were straightforward to classify and there were barely any borderline cases.
Figure  shows the results of the experiment. The figure consists of four graphs. Each
graph is a plot of precision versus recall, at different points in time, as
indicated by the label. When a search is performed, the articles are effectively
sorted by their similarity scores. If all the articles are retrieved for the
user, the recall is
shows the results of the experiment. The figure consists of four graphs. Each
graph is a plot of precision versus recall, at different points in time, as
indicated by the label. When a search is performed, the articles are effectively
sorted by their similarity scores. If all the articles are retrieved for the
user, the recall is ,
but the precision is very low. If none of the articles are retrieved, recall
is
, but the precision
is
. For intermediate
numbers of articles retrieved, different values of recall and precision will
be observed. By using the number of articles as a parameter, a graph can be
drawn connecting the set of all possible precision-recall pairs. The graphs
help us compare the performances of the each search for all possible values
of the parameter.
Initially, when the profile is empty, the articles retrieved are in a
random order. The graph for the initial profile (labeled ``'')
is the result when all articles are scored zero since none of them
match the empty profile. Since this iteration is a random ordering of
articles, it is possible that none of the retrieved articles are
relevant. In that case, the user needs to program the agent by
demonstration by providing a few examples of relevant documents.
After feedback is provided to the relevant articles, the profile is
modified and the search is performed again. The search is much
improved and the result is shown by the next line graph (labeled
``
''). Successive iterations keep improving the performance of
the search.
The profile is quite successful at converging on the terms commonly occurring
in articles relating to ``China''. This can be seen from the final (at )
profile as shown in Table
.
It can be seen that given an empty initial profile (so there is nothing to
unlearn) and with consistent user feedback the system is successful at specializing
to user interests. The caveat is that the user interest must be amenable to
a keyword-based description (see Chapter ).