


The action selection process is completely `open'. The environment as well as the goals may change at run time. As a result, the external input/output as well as the internal activation/inhibition patterns will change reflecting the modified situation. Even more, the external influence during `planning' or spreading activation is so important that plans are only formed as long as the influence or input/output (or `disturbance') from the environment and goals is present.
Because of this continuous `reevaluation', the action selection behavior adapts easily to unforeseen or changing situations. For example, if after the activation of module `pick-up-board', the board is not in the robot's hand (e.g. because it slipped away), the same competence module becomes active once more, because it still receives a lot of activation from the competence modules that want the board to be in the robots hand. Or if there would be a second module which can make that condition become true, than that one will be tried (because `pick-up-board's activation level will have been reset to 0). Serendipity is another example of this ability to adapt. If a goal or subgoal would suddenly appear to be fulfilled, the modules that contributed to this goal will no longer be activated. All of these experiments have been simulated with success. Notice that such unforeseen events do not mean that the system has to `drop' the ongoing plan and `build' a new one. Actually the system continuously weighs off the different alternatives. When some condition changes, this may have the effect that an alternative (sub-)plan becomes more attractive (more activated) than the current one.
Notice also that it is not the case that the system replans at every
timestep. The `history' of the spreading activation also plays a role in the
action selection behavior since the activation levels are not reinitialized at
every timestep. So just like there is a tradeoff between goal-orientedness
and state-orientedness, we here have a tradeoff between adaptivity and bias
towards the ongoing plan (see also next section). One can smoothly mediate
among the two extremes by selecting a particular ratio of the parameters
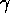 and
and 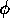 versus
versus  (the mean level of activation). Consider
as an example the modules of figure
(the mean level of activation). Consider
as an example the modules of figure  . The initial state is
. The initial state is
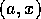 , the
goal is
, the
goal is 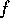 .
.
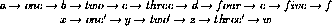
Figure: A toy network to test adaptivity versus bias (inertia).
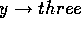 stands for proposition
stands for proposition  is a precondition of module
is a precondition of module 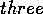 ,
while
,
while 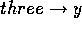 stands for proposition
stands for proposition 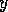 is in the add-list of module
is in the add-list of module 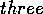 .
.
After module `one' had been active, we added 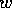 to the global
goals. When
to the global
goals. When 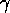 and
and 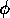 are relatively small
in comparison with
are relatively small
in comparison with  , the internal spreading activation
has more impact than the influence from the state of the environment and
the global goals. The resulting action selection behavior is therefore
less adaptive. Concretely in this example it means that, although for goal
, the internal spreading activation
has more impact than the influence from the state of the environment and
the global goals. The resulting action selection behavior is therefore
less adaptive. Concretely in this example it means that, although for goal
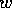 the path from state to goals is shorter, the system
continues working on goal
the path from state to goals is shorter, the system
continues working on goal 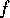 , and only after
, and only after 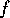 is achieved, start
working on goal
is achieved, start
working on goal 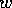 (cfr. figure ). Again the appropriate
solution lies somewhere in the middle. The parameters should be chosen such
that the system does not jump between different goals all the
time, but that it does exploit opportunities and adapts to changing
situations.
(cfr. figure ). Again the appropriate
solution lies somewhere in the middle. The parameters should be chosen such
that the system does not jump between different goals all the
time, but that it does exploit opportunities and adapts to changing
situations.

Figure: The action selection behavior can be made less adaptive and more
biased towards ongoing plans by choosing 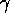 and
and 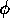 relatively small in comparison with
relatively small in comparison with  as in the first
experiment. After module
as in the first
experiment. After module 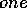 had been active, we added the goal
had been active, we added the goal 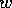 .
Although there are less modules required to achieve this goal, the system
continues working on goal
.
Although there are less modules required to achieve this goal, the system
continues working on goal 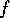 . In the second experiment, the system is
less biased towards ongoing goals, because
. In the second experiment, the system is
less biased towards ongoing goals, because 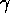 and
and 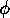 are relatively high in comparison with
are relatively high in comparison with  .
.
Notice finally that the algorithm also exhibits another type of adaptivity, namely fault tolerance. This is a consequence of the distributed nature of the algorithm. Since no one of the modules is more important than the others, the networks are still able to perform under degraded preconditions. It is possible to delete competence modules and the network still does whatever is within its remaining capabilities. For example, when `put-board-in-vise' is deleted or made inactive, the network comes up with a solution that does not involve this module.