


The algorithm activates the modules that are relevant to the current
situation more than the ones that are not.
The processes responsible for this are
the input of activation energy coming from the state of the environment
and the spreading of activation energy by executable modules towards
their successors (which implements some sort of prediction of what will be true next). As already mentioned
in the previous section, the advantages are that (1) the system biases its
search and thereby speeds up the action selection and (2) the system is
able to exploit opportunities (let its action selection be driven more by
what is happening in the environment). The importance of (2) for an
autonomous agent has recently been recognized by the AI community as is
witnessed by the growth of interest in so-called reactive systems. The
characteristic of situation-orientedness can be exploited to a higher or
lesser degree by varying the parameter 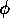 . Figure
. Figure  shows the results of experiments with different ratios for the parameters
shows the results of experiments with different ratios for the parameters
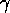 and
and 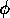 .
.

Figure: These results show that one can mediate between
goal-orientedness of the action selection and data-orientedness
by varying the ratio of 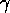 to
to 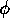 . In
the first experiment, the network performs traditional backward chaining
(
. In
the first experiment, the network performs traditional backward chaining
(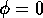 ). In the second experiment there is some
forward spreading going on, but
). In the second experiment there is some
forward spreading going on, but 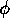 is still smaller than
is still smaller than
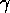 . The input from the state and forward spreading bias the
search so that the action selection is now much faster. The resulting action
selection is however less optimal (the action selection is more data-driven,
which makes that actions that are not relevant to the goal may get selected,
e.g. in this case, `find-place' is activated a second time).
. The input from the state and forward spreading bias the
search so that the action selection is now much faster. The resulting action
selection is however less optimal (the action selection is more data-driven,
which makes that actions that are not relevant to the goal may get selected,
e.g. in this case, `find-place' is activated a second time).
The forward spreading rules take care that a module receives activation from the state in
proportion to how `close' it is to being executable given the current state
of the environment. A module is closest to being executable if it really is
executable (i.e., if all its preconditions are fulfilled). For non-executable
modules, `closeness' is inversely proportional to the weighted sum of the
lengths of a path from executable modules to the module itself for each of
the preconditions of the module. This implies for
example, that a module that has two preconditions 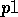 and
and
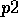 of which one, for example
of which one, for example 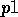 , cannot be made
true given the current state, receives relatively less activation from the
state and, therefore, has less probability of being part of a `plan'
, cannot be made
true given the current state, receives relatively less activation from the
state and, therefore, has less probability of being part of a `plan' .
.